General Accelrator Renderer(GAR)¶
A minimal RISC-V GPU implementation in Verilog built by cal poly CARP on top of the tiny-gpu architecture
Table of Contents¶
Overview¶
This project is built on top of the tiny-gpu by adam maj, it is important to go through his read me to understand the fondation of our project.
The goal of this project is to help introduce cal poly CARP student to GPU architecture with getting hands on expence with building, designing and verification on a GPU.
Our current project is expanding the ISA to acomidate RISC-V and to be able to take advantage of the compiler built by the vortex team at georgia tech.
Whats New in GAR?¶
[!IMPORTANT]
Current GAR expantions Make sure to read and understand the orginal tiny-gpu before starting to got throught the GAR core because every thing we do is going to build off that
Warp schedular - this adition allows for a paramatraizable warp size that is composed from the thread block that is scheduled onto the compute core, but also has warps scheduled in a round robin fasion a
Architecture¶
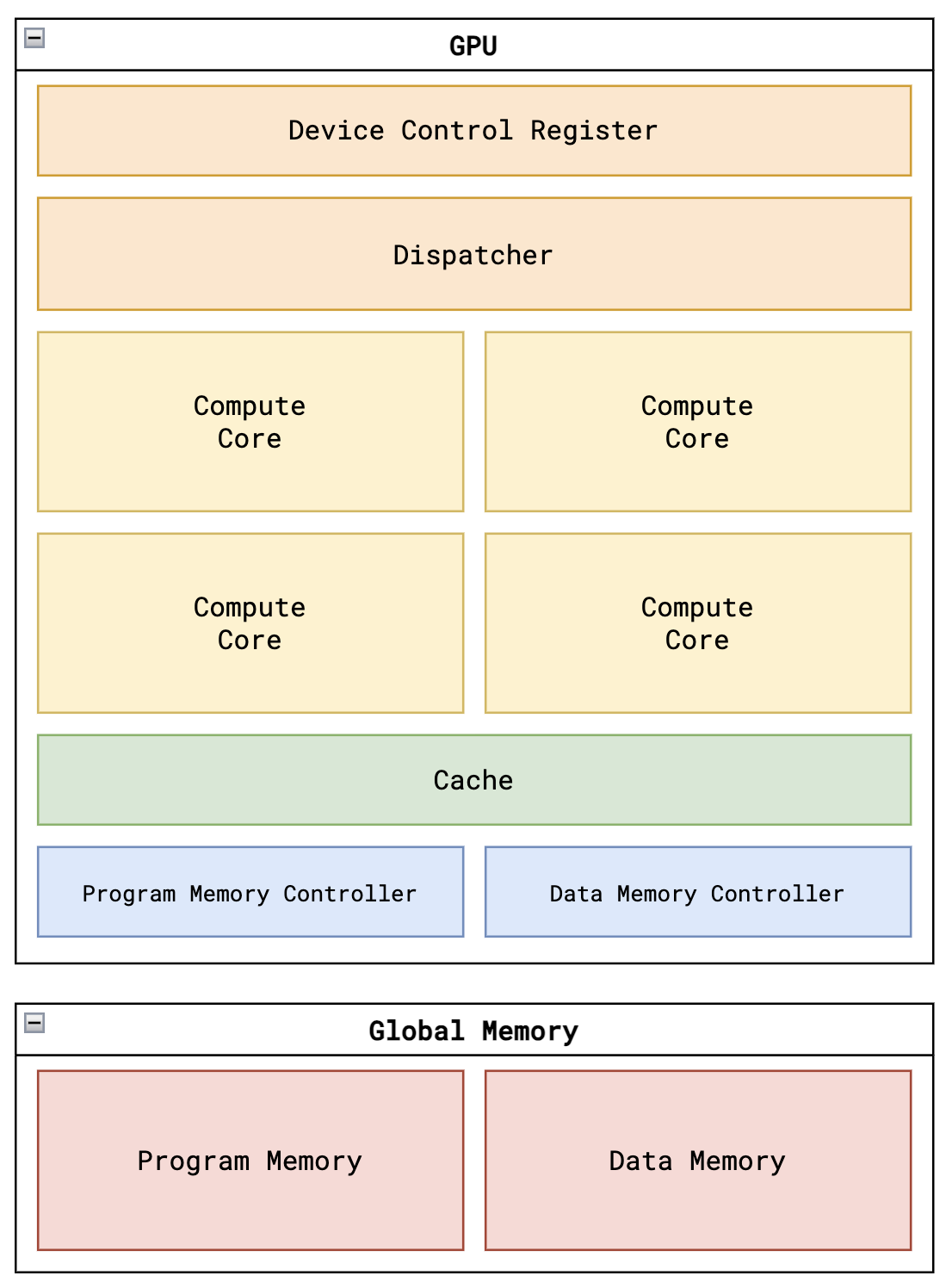
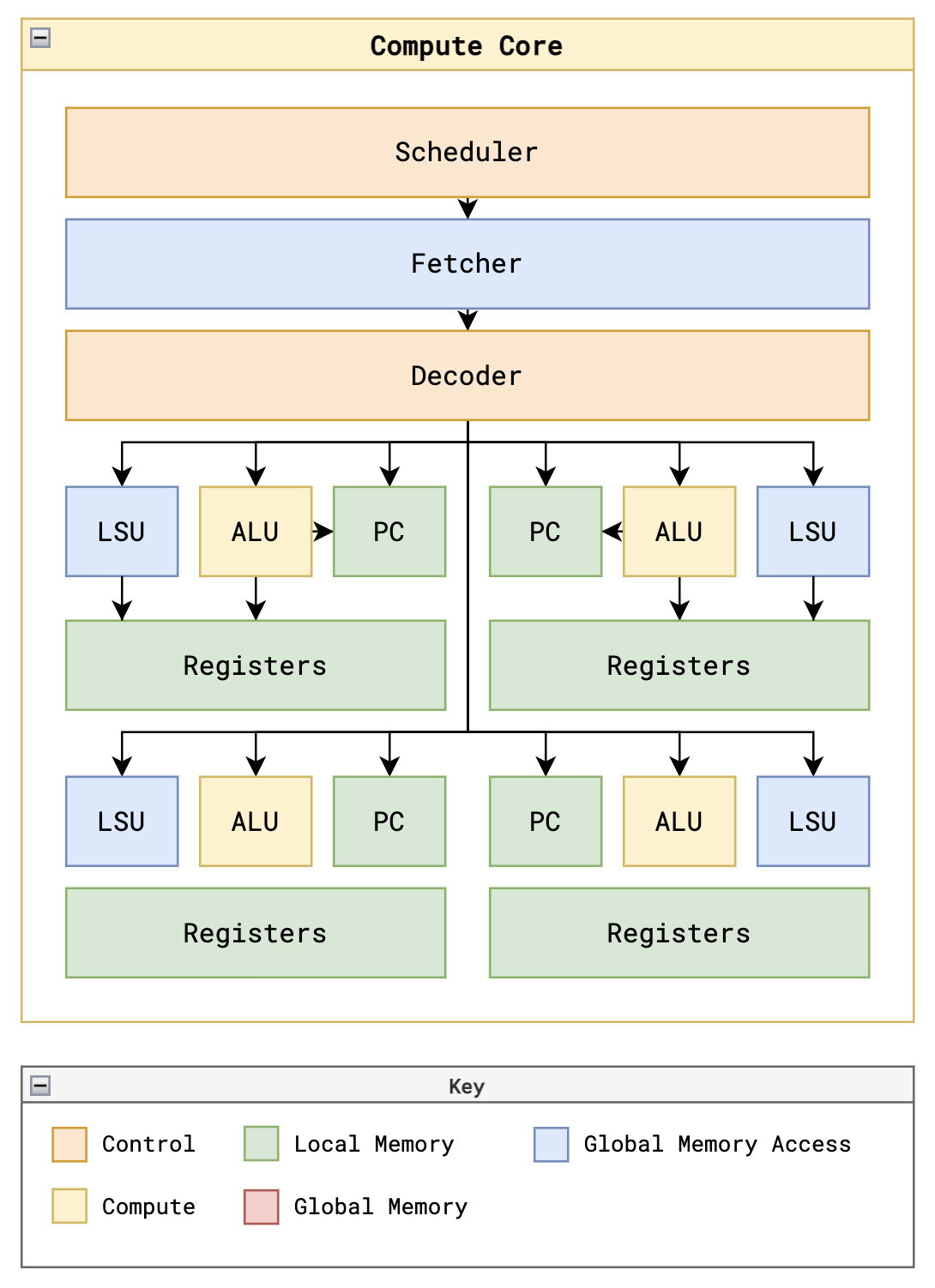
GPU¶
For the current GAR project these are the changes that need to be made to each of the following modules
Device control register
Decoder
LSU
ALU
PC
Device Control Register¶
The device control register need to be changed to store metadata specifying how kernels should be executed on the GPU.
Dispatcher¶
None
Memory¶
TBD
Global Memory¶
TBD
Memory Controllers¶
None
Cache (WIP)¶
None
Core¶
Changes
Warp Scheduler¶
None
Fetcher¶
None
Decoder¶
Changed to properly decode the RISC-V isa
Register Files¶
None
ALUs¶
Needs to be expanded to compute a larger set of the RISC-V isa
LSUs¶
Expand the ISA it incorrpetate the more complete RISC-V isa
PCs¶
Expand to compute more branching instructions
ISA¶
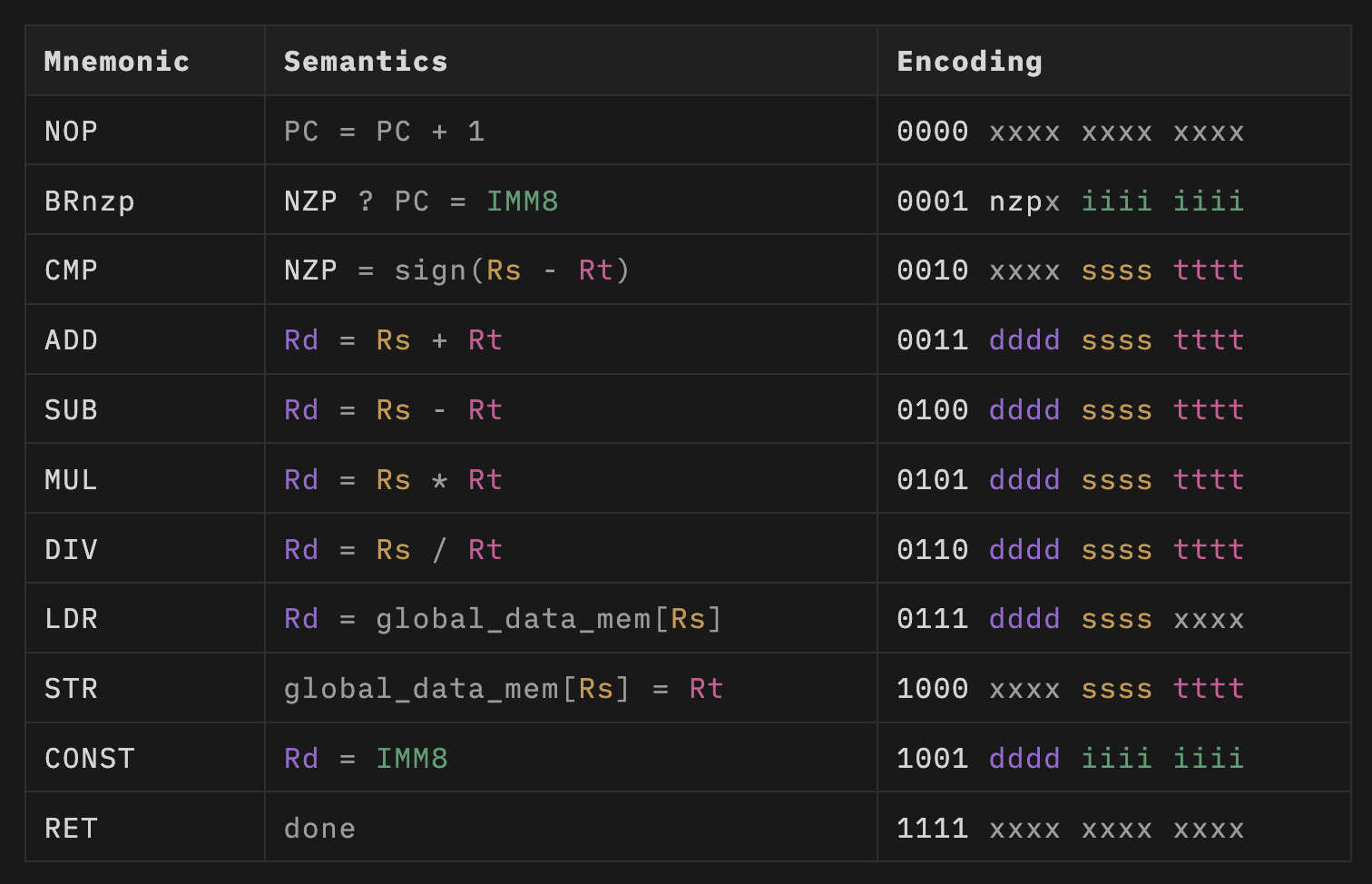
Execution¶
Core¶
Each core follows the following control flow going through different stages to execute each instruction:
FETCH- Fetch the next instruction at current program counter from program memory.DECODE- Decode the instruction into control signals.REQUEST- Request data from global memory if necessary (ifLDRorSTRinstruction).WAIT- Wait for data from global memory if applicable.EXECUTE- Execute any computations on data.UPDATE- Update register files and NZP register.
The control flow is laid out like this for the sake of simplicity and understandability.
In practice, several of these steps could be compressed to be optimize processing times, and the GPU could also use pipelining to stream and coordinate the execution of many instructions on a cores resources without waiting for previous instructions to finish.
Thread¶
Simulation¶
tiny-gpu is setup to simulate the execution of both of the above kernels. Before simulating, you’ll need to install iverilog and cocotb:
Install Verilog compilers with
brew install icarus-verilogandpip3 install cocotbDownload the latest version of sv2v from https://github.com/zachjs/sv2v/releases, unzip it and put the binary in $PATH.
Run
mkdir buildin the root directory of this repository.
Once you’ve installed the pre-requisites, you can run the kernel simulations with make test_matadd and make test_matmul.
Executing the simulations will output a log file in test/logs with the initial data memory state, complete execution trace of the kernel, and final data memory state.
If you look at the initial data memory state logged at the start of the logfile for each, you should see the two start matrices for the calculation, and in the final data memory at the end of the file you should also see the resultant matrix.
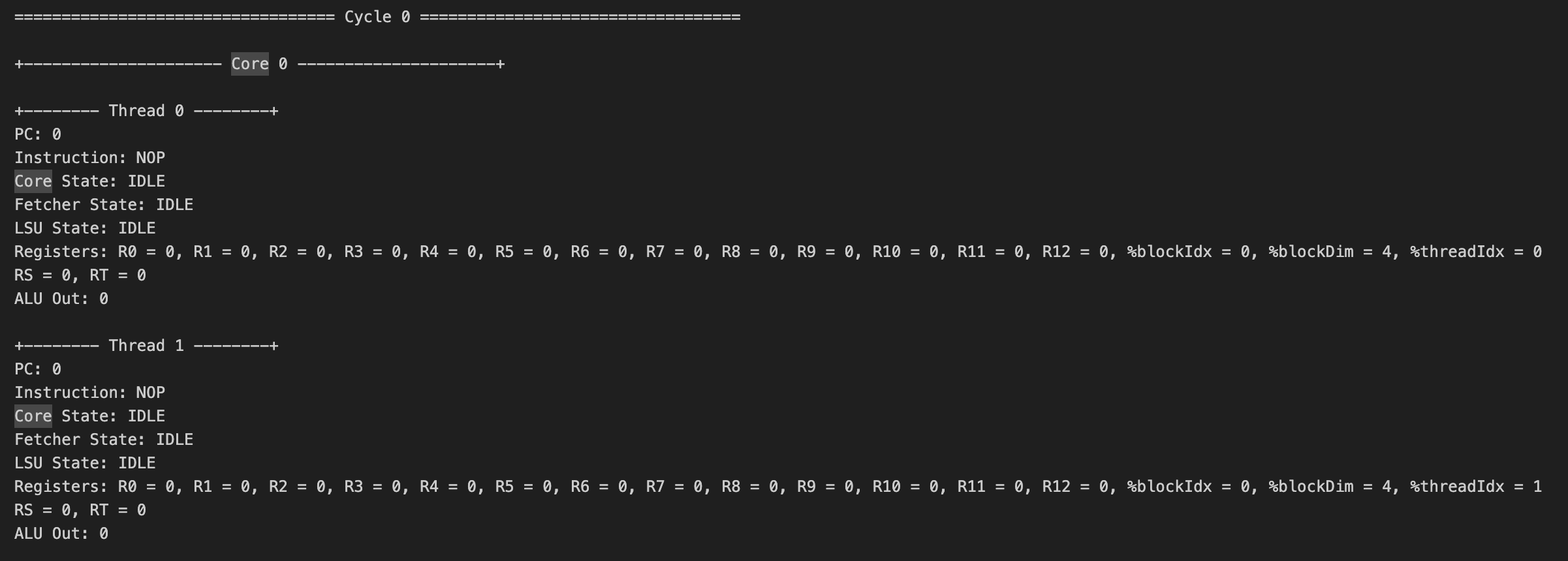
Below is a sample of the execution traces, showing on each cycle the execution of every thread within every core, including the current instruction, PC, register values, states, etc.
For anyone trying to run the simulation or play with this repo, please feel free to DM me on twitter if you run into any issues - I want you to get this running!
Future CARP GAR projects¶
Memory Coalescing¶
Another critical memory optimization used by GPUs is memory coalescing. Multiple threads running in parallel often need to access sequential addresses in memory (for example, a group of threads accessing neighboring elements in a matrix) - but each of these memory requests is put in separately.
Memory coalescing is used to analyzing queued memory requests and combine neighboring requests into a single transaction, minimizing time spent on addressing, and making all the requests together.
Pipelining¶
In the control flow for tiny-gpu, cores wait for one instruction to be executed on a group of threads before starting execution of the next instruction.
Modern GPUs use pipelining to stream execution of multiple sequential instructions at once while ensuring that instructions with dependencies on each other still get executed sequentially.
This helps to maximize resource utilization within cores as resources are not sitting idle while waiting (ex: during async memory requests).
Branch Divergence¶
tiny-gpu assumes that all threads in a single batch end up on the same PC after each instruction, meaning that threads can be executed in parallel for their entire lifetime.
In reality, individual threads could diverge from each other and branch to different lines based on their data. With different PCs, these threads would need to split into separate lines of execution, which requires managing diverging threads & paying attention to when threads converge again.
Synchronization & Barriers¶
Another core functionality of modern GPUs is the ability to set barriers so that groups of threads in a block can synchronize and wait until all other threads in the same block have gotten to a certain point before continuing execution.
This is useful for cases where threads need to exchange shared data with each other so they can ensure that the data has been fully processed.
Next Steps¶
Updates I want to make in the future to improve the design, anyone else is welcome to contribute as well:
[ ] Add a simple cache for instructions
[ ] Build an adapter to use GPU with Tiny Tapeout 7
[ ] Add basic branch divergence
[ ] Add basic memory coalescing
[ ] Add basic pipelining
[ ] Optimize control flow and use of registers to improve cycle time
[ ] Write a basic graphics kernel or add simple graphics hardware to demonstrate graphics functionality
For anyone curious to play around or make a contribution, feel free to put up a PR with any improvements you’d like to add 😄